
I risultati di un’indagine svolta a livello globale su un dataset di 8326 stazioni –
Leggendo i riferimenti bibliografici in lavori più recenti mi sono imbattuto in questo lavoro di Westra et al. (Westra_et_al_2013 Global Increasing Trends in Annual Maximum Daily Precipitation) che molti utilizzano ormai come lavoro di riferimento per affermare che l’aumento delle temperature globali conduce ad una aumento delle precipitazioni estreme. Ho pertanto ritenuto utile leggere l’articolo ed analizzarlo criticamente ed in tale lavoro ho coinvolto l’amico Sergio Pinna, che ringrazio per le utili considerazioni espresse.
Cosa emerge dal lavoro
Il lavoro verte sull’analisi dei trend delle precipitazioni giornaliere massime annue dal 1900 al 2009 (110 anni in tutto), eseguito su un totale di 8326 stazioni terrestri che gli autori definiscono di “alta qualità”, scelte da un dataset iniziale di 11391 stazioni da cui sono state escluse quelle le cui serie storiche erano troppo brevi. In sostanza dunque, per ogni stazione si è ricavato anno per anno il valore giornaliero massimo ed ognuna delle 8326 serie storiche così ottenute è stata sottoposta ad analisi di trend.
Da tale analisi emerge che delle stazioni analizzate il 36% mostra un trend lineare negativo ed il 64% un trend positivo.
Dal test statistico non parametrico di Mann Kendall (di qui in avanti indicato come “test MK”) per la verifica delle significatività di tali trend emerge inoltre che l’89.4% delle stazioni non presenta trend significativi, l’8.6% presenta trend positivo significativo ed il 2% trend negativo significativo.
Gli autori formulano allora l’ipotesi nulla (H0) secondo cui l’insieme delle stazioni non presenti trend positivi o negativi. Per verificare la veridicità di H0 si generano 1000 serie fittizie per permutazione delle serie vere e si valuta come dovrebbero distribuirsi i trend perché H0 fosse dimostrata. In tal senso si verifica che:
- il 2% delle serie dovrebbe avere un significativo trend positivo ed il 2% un significativo trend negativo (valori riscontrati: 8.6% per i trend positivi e 2% per i negativi)
- il 50% dovrebbe avere trend positivo ed il 50% trend negativo (valori riscontrati: 64% e 36%)
Da ciò gli autori deducono che H0 non è rispettata e che dunque il trend complessivo è da ritenere positivo. Per inciso nella seconda parte del lavoro si analizza la correlazione esistente fra trend precipitativo e trend termico dimostrando che è l’aumento delle temperature globali a spingere all’aumento le precipitazioni massime.
Analisi critica
Lo schema logico applicato dagli autori mi lascia perplesso in quanto un 89.4% di trend non significativi è una grossa cifra, nel senso che l’89.4% delle stazioni e dunque l’89.4% della superficie del pianeta (ammettendo una distribuzione geografica omogenea della rete considerata) non manifesta trend. Questo mi pare il risultato più rilevante del lavoro, risultato che viene sottaciuto negli abstract ove si parla invece di un 36% di trend negativi e di un 64% di positivi, un dato che mi pare del tutto ideologico, trattandosi in gran parte di trend statisticamente non significativi.
Ciò per inciso spiega il titolo “provocatorio” che ho voluto dare a questo mio scritto, titolo da cui deriva la domanda fatidica: quale destino avrebbe avuto il loro lavoro se gli autori avessero adottato un titolo simile al mio e che mi pare del tutto legittimo alla luce dei dati? Permettetemi di dubitare che il loro lavoro sarebbe stato pubblicato…. Ma, andando oltre queste umane miserie, penso che occorra a mio avviso interrogarsi su almeno un paio di altri temi e cioè:
- Sulla robustezza del test MK rispetto ad outlyers. Ciò in quanto nei decenni più recenti la qualità delle serie storiche di precipitazione è andata degradando in modo preoccupante, specie con l’introduzione di strumentazione automatica che si basa su strumenti intrinsecamente insicuri come i pluviometri a doppia bascula.
- Sulla robustezza di quanto emerge dal test MK rispetto al variare della lunghezza delle serie storiche. Se ad esempio si avesse una recrudescenza di eventi estremi nel ventennio 1961 – 1970 il risultato sarebbe un trend positivo se rapportato all’intero periodo 1901-2012 e che tuttavia diverrebbe negativo se rapportato al periodo 1951-2012. Tale domanda me la pongo alla luce del diagramma di figura 1 da cui emerge il dubbio circa la sensatezza di operare su dataset così disuniformi in termini di arco temporale coperto, anche perché la disuniformità temporale si trascina inevitabilmente dietro la disomogeneità di metodi di misura e di qualità dei dati.
Se poi si guardano le carte della distribuzione geografica delle stazioni a diverso livello di correlazione (non significativa, significativamente positiva o negativa) fra trend pluviometico e trend termico (di qui in avanti la chiamerò “correlazione T-P”) ci si accorge che nella stessa area geografica convivono stazioni con comportamenti totalmente diversi e che inoltre si evidenzia una variabilità spaziale di mesoscala (in particolare in Europa) che in teoria non dovrebbe sussistere: come mai (figura 1) per l’area italiana solo una ridotta zona del bacino padano (Emilia) presenta stazioni con correlazione T-P positiva significativa ed una altrettanto ridotta zona (la Romagna) presenta correlazione T-P positiva negativa? Come mai tutto il resto d’Italia (salvo Catania) manifesta correlazione T-P nulla? Come mai sulla carta globale compare una stazione con correlazione T-P positiva significativa al largo della Libia in una zona ove non vi sono isole? Come mai il confine francese con Germania e Benelux (quasi del tutto privo di barriere orografiche) segna un cambiamento così radicale di comportamento nella correlazione T-P e come mai lo stesso curioso fenomeno si ripresenta al confine fra Germania e Polonia?
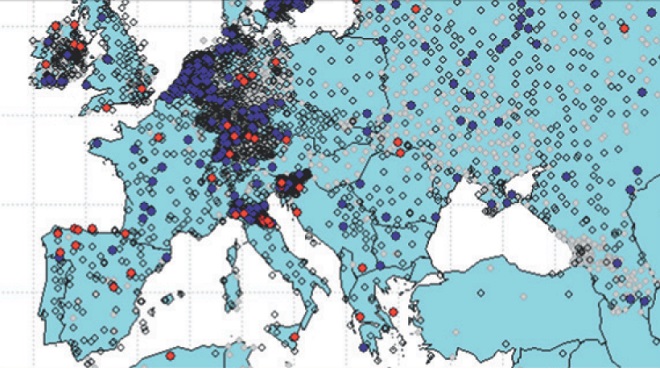
Un tale giochino potrebbe proseguire in altre parti del mondo e suscita in me il dubbio che la qualità del dato unita alla differente lunghezza delle serie abbia creato artefatti di cui gli autori non mi pare si siano fatti carico. In sostanza si tratta di dubbi che l’articolo a mio avviso non chiarisce e che mi inducono a pensare che l’unico modo per fugarli sarebbe quello di ripetere l’analisi sulle stesse serie.
A conclusione di questo scritto ritengo utile segnalare che i lavori scientifici devono essere contestati sul piano scientifico ed in tal senso si evidenziano enormi spazi per una ricerca non ideologica dedicata al legame fra temperature e precipitazioni e svolta su serie storiche di lunghezza comparabile e validate in modo rigoroso.

Concordo sul fatto che il risultato importante del lavoro è che la (stra)grande maggioranza delle stazioni non mostra trend significativi: basta guardare la fig.5 e le figure successive. Mi associo anche alle “illazioni” di L. Mariani sulla possibilità di pubblicare questo lavoro con un titolo diverso e più aderente ai risultati effettivamente trovati.
Una curiosità: credo che il test MK (come altri test non parametrici) nasca dall’impossibilità di conoscere la distribuzione di probabilità dei singoli dati e dall’assunzione, invece, che le differenze tra i valori (Eq.1) abbiano distribuzione uniforme e che quindi si possa calcolare la distribuzione dell’Eq.2 (cioè della variabile di test) essendo nota la distribuzione dell’Eq.1.
L’ipotesi è ragionevole nella maggioranza dei casi, ma mi chiedo se la grande varietà delle situazioni logistiche e della strumentazione presente in una analisi globale come questa, possa ancora garantire che le differenze mantengano una distribuzione uniforme e quindi l’applicabilità del test.